Abstract
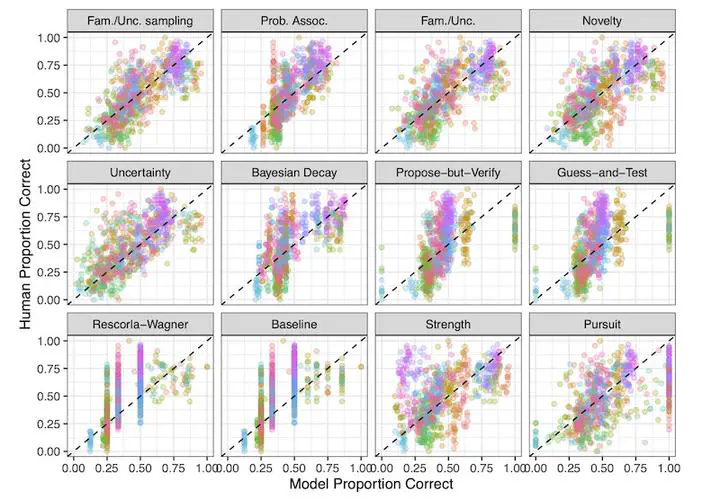
One problem language learners face is extracting word meanings from scenes with many possible referents. Despite the ambiguity of individual situations, a large body of empirical work shows that people are able to learn cross-situationally when a word occurs in different situations. Many computational models of cross-situational word learning have been proposed, yet there is little consensus on the main mechanisms supporting learning, in part due to the profusion of disparate studies and models, and lack of systematic model comparisons across a wide range of studies. This study compares the performance of several extant models on a dataset of 44 experimental conditions and a total of 1,696 participants. Using cross-validation, we fit multiple models representing theories of both associative learning and hypothesis-testing theories of word learning, find two best-fitting models, and discuss issues of model and mechanism identifiability. Finally, we test the models’ ability to generalize to additional experiments, including developmental data.